
robots.txt,是一个给搜索引擎机器人下指令的文本文件,用于SEO优化。
如果用对了,可以确保搜索引擎机器人(也叫爬虫或蜘蛛)正确抓取和索引你的网站页面。
如果用错了,可能会对SEO排名和网站流量造成负面影响,那怎么设置robots.txt文件才算正确?一灯今天就和大家分享下一点心得,内容主要包括以下几个方面。
1. robots.txt是什么?
robots.txt是一个放在网站根目录的纯文本文件,需要自己添加,如下图所示。
如果你网站的域名是www.abc.com,robots.txt的查看地址是www.abc.com/robots.txt。
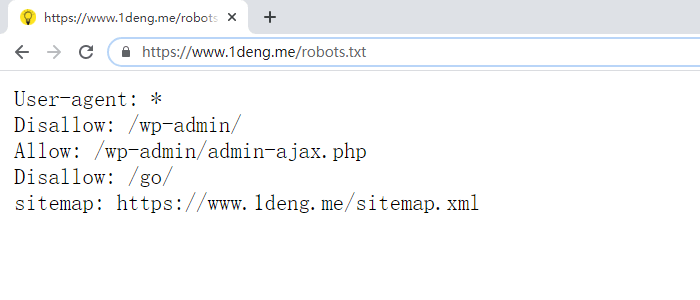
robots.txt里包含了一组搜索引擎机器人指令。
当搜索引擎机器人访问你网站时,首先会查看robots.txt文件里的内容,然后根据robots.txt的指示进行网站页面的抓取和索引,进而收录某些页面,或不收录某些页面。
需要注意的是,robot.txt文件不是那种强制性、必须要做的设置。至于做与不做,为什么要做,做了有什么用,我接下来为大家详细解释。
2. robots.txt对SEO有什么用?
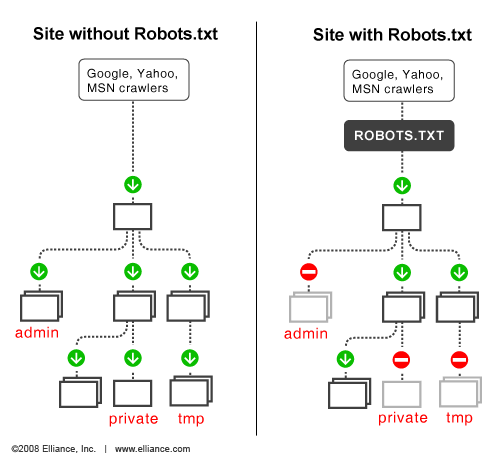
简单的说,robots.txt有两个功能,允许和阻止搜索引擎机器人抓取你的网站页面。如果没有的话,搜索引擎机器人将对整个网站进行爬行,包括网站根目录的所有数据内容。
具体的工作原理可以参考elliance的说明,如下图所示。
1993年,互联网才起步没多久,能被发现的网站少之又少,Matthew Gray编写了一个蜘蛛爬虫程序World Wide Web Wanderer,目的是发现收集新网站做网站目录。
但后面搞爬虫的人不仅是收集网站目录这么简单,还会抓取下载大量网站数据。
同年7月,Aliweb创始人Martijn Koster的网站数据被恶意抓取,于是他提出了robots协议。
目的是告诉蜘蛛爬虫,哪些网页可以爬行,哪些网页不可以爬行,特别是那些不想被人看到的网站数据页面。经过一系列的讨论,robots.txt正式走上历史舞台。

从SEO角度来说,刚上线的网站,由于页面较少,robots.txt做不做都可以,但随着页面的增加,robots.txt的SEO作用就体现出来了,主要表现在以下几个方面。
- 优化搜索引擎机器人的爬行抓取
- 阻止恶意抓取,优化服务器资源
- 减少重复内容出现在搜索结果中
- 隐藏页面链接出现在搜索结果中
3. robots.txt怎么写才符合SEO优化?

首先,robots.txt文件没有默认格式。
robots.txt的写法包括User-agent,Disallow,Allow和Crawl-delay。
- User-agent: 后面填你要针对的搜索引擎,*代表全部搜索引擎
- Disallow: 后面填你要禁止抓取的网站内容和文件夹,/做前缀
- Allow: 后面填你允许抓取的网站内容,文件夹和链接,/做前缀
- Crawl-delay: 后面填数字,意思是抓取延迟,小网站不建议使用
举个例子,如果你要禁止谷歌机器人抓取你网站的分类,写法如下:
User-agent: googlebot
Disallow: /category/
举个例子,如果你要禁止所有搜索引起抓取wp登陆链接,写法如下:
User-agent: *
Disallow: /wp-admin/
举个例子,如果你只允许谷歌图片抓取你的wp网站图片,写法如下:
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
更具体的写法,大家可以参考谷歌robots.txt官方文档,如下图所示。

虽然这些写法指令看上去很复杂,但只要你使用的是WordPress,就会变的简单许多,毕竟wp是谷歌的亲儿子,就SEO而言WordPress网站的robots.txt最佳写法如下,需要用文本编辑。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.yourdomain.com/sitemap.xml
或者是下面这个样子。
User-agent: *
Allow: /
Sitemap: https://www.yourdomain.com/sitemap.xml
两者的区别是要不要禁止抓取/wp-admin/。
关于/wp-admin/,2012年WordPress增加了一个新标记@header( 'X-Robots-Tag: noindex' ),效果和用robots.txt禁止抓取/wp-admin/一样,如果还是不放心的话,可以加上。
至于其它不想被搜索引擎抓取的网站内容和链接,根据自己网站的需求来做就行了。
可以使用robots.txt禁止抓取,也可以使用Meta Robots做Noindex。我个人的看法是wp程序自带链接用Meta Robots,需要隐藏的网站内容页面用robots.txt。
总结
接下来要做的是把写好的robots.txt文件添加到WordPress网站。
根据我自己的经验,robots.txt的指令越少越好,在我还是小白的时候看了一些大神的文章,把很多文件目录和网站内容都禁止了,特别是/wp-includes/,直接导致JS和CSS无法正常运行。
最后,要注意的是robots.txt文件里的指令是分大小写的,不要弄错了。


谢谢分享